-
PostgreSQL 03: 프로세스 & 메모리 아키텍처 심화 (오라클 비교)DB 스터디/PostgreSQL 2026. 4. 1. 17:53
실습 환경
OS Ubuntu 22.04 Server PostgreSQL 14 CPU 2코어 RAM 2GB 디스크 40GB 선행 조건 PostgreSQL 01, 02 실습 완료
목차
1. PostgreSQL 프로세스 구조
2. 백그라운드 프로세스
3. 메모리 구조 — Shared Memory vs Local Memory
4. WAL(Write-Ahead Log) 동작 원리
5. MVCC — 오라클 Undo와의 구조적 차이
6. VACUUM — PostgreSQL만의 유지보수 메커니즘
1. PostgreSQL 프로세스 구조
- 오라클은 단일 프로세스 안에서 내부 스레드로 동작하지만, PostgreSQL은 멀티 프로세스 구조로 동작
- 클라이언트 접속마다 독립된 백엔드 프로세스가 fork()로 생성됨
구분 오라클 PostgreSQL 프로세스 모델 단일 인스턴스 프로세스 + 내부 스레드 멀티 프로세스 (fork 기반) 클라이언트 접속 Dedicated Server / Shared Server 접속마다 Backend Process fork 관리 주체 프로세스 PMON, SMON, DBWn 등 postmaster 최대 접속 수 제한 sessions 파라미터 max_connections 파라미터 -- 현재 실행 중인 PostgreSQL 프로세스 전체 확인 (OS 레벨) ps aux | grep postgres -- 출력 예시 postgres 2929 ... postgres: checkpointer postgres 2930 ... postgres: background writer postgres 2931 ... postgres: walwriter postgres 2932 ... postgres: autovacuum launcher postgres 2933 ... postgres: stats collector postgres 2934 ... postgres: logical replication launcher
OS에서 PostgreSQL 프로세스 전체 확인 -- PostgreSQL 내부에서 백엔드 프로세스 확인 (pg_stat_activity) SELECT pid, usename, application_name, state, wait_event_type, wait_event FROM pg_stat_activity;
pg_stat_activity로 백엔드 프로세스 확인
2. 백그라운드 프로세스
- postmaster(=postgres 메인 프로세스)가 기동 시 백그라운드 프로세스들을 자동으로 띄움
- 오라클의 PMON/SMON/DBWn/LGWR에 대응하는 개념
PostgreSQL 프로세스 역할 오라클 대응 checkpointer 주기적으로 dirty page를 디스크에 flush (체크포인트 수행) DBWn + CKPT background writer checkpointer 부하 분산 — dirty page를 미리 조금씩 flush DBWn walwriter WAL 버퍼를 주기적으로 WAL 파일에 기록 LGWR autovacuum launcher VACUUM 필요한 테이블 감지 후 autovacuum worker 실행 SMON (일부) stats collector 테이블/인덱스 접근 통계 수집 AWR/MMON (일부) logical replication launcher 논리 복제 worker 관리 LogMiner 관련 -- 체크포인트 통계 확인 -- checkpoint_write_time, checkpoint_sync_time이 높으면 I/O 병목 신호 SELECT checkpoints_timed, checkpoints_req, checkpoint_write_time, checkpoint_sync_time, buffers_checkpoint, buffers_clean, buffers_backend FROM pg_stat_bgwriter;
체크포인트 통계 확인 결과 -- WAL writer 활동 확인 SELECT pg_current_wal_lsn() AS current_lsn, pg_walfile_name(pg_current_wal_lsn()) AS current_wal_file;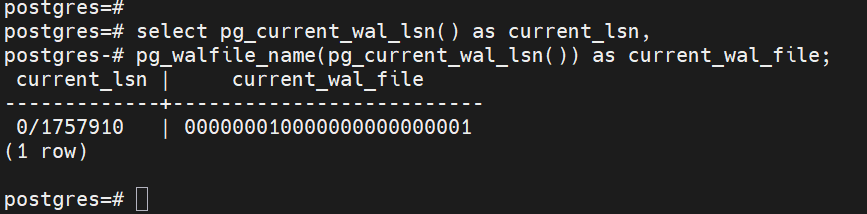
WAL writer 활동 확인
3. 메모리 구조 — Shared Memory vs Local Memory
- 오라클은 SGA(공유) + PGA(프로세스별) 구조
- PostgreSQL도 동일하게 Shared Memory(공유) + Local Memory(백엔드 프로세스별) 로 나뉨
구분 오라클 PostgreSQL 공유 메모리 (전체) SGA Shared Memory 버퍼 캐시 Buffer Cache (SGA) shared_buffers 리두/WAL 버퍼 Redo Log Buffer (SGA) WAL buffers 프로세스별 메모리 PGA Local Memory (per backend) 정렬/해시 작업 sort_area_size (PGA) work_mem 유지보수 작업 — maintenance_work_mem 3-1. Shared Memory 핵심 파라미터 확인
-- postgres 계정으로 psql 접속 sudo -i -u postgres psql -- 공유 메모리 관련 파라미터 한 번에 확인 SHOW shared_buffers; -- 오라클 Buffer Cache에 해당 SHOW wal_buffers; -- WAL 버퍼 크기 SHOW effective_cache_size; -- OS 페이지 캐시 포함 플래너 힌트용 (실제 할당 아님) -- [결과 예시] -- shared_buffers = 128MB ← 기본값 (실무에서는 전체 RAM의 25% 권장) -- wal_buffers = 4MB ← 기본값 -- effective_cache_size = 4GB
공유 메모리 관련 파라미 확인 3-2. Local Memory 핵심 파라미터 확인
SHOW work_mem; -- 정렬, 해시조인 등 연산 시 백엔드 프로세스별 할당 SHOW maintenance_work_mem; -- VACUUM, CREATE INDEX 시 사용 -- [결과 예시] -- work_mem = 4MB ← 기본값 (복잡한 쿼리 환경에서는 16~64MB 권장) -- maintenance_work_mem = 64MB ← 기본값 -- 주의: work_mem은 쿼리 안의 정렬/해시 연산 단계마다 독립적으로 할당됨 -- 동시 접속 100명 × work_mem 64MB × 연산 단계 수 → 메모리 폭발 가능 -- max_connections와 반드시 함께 고려해야 함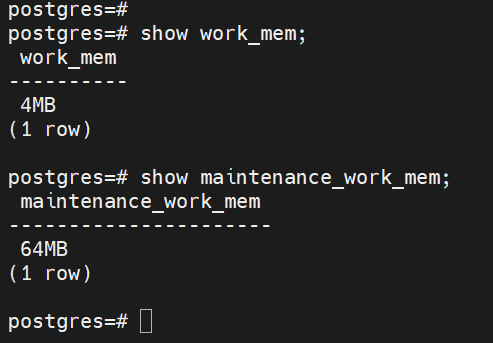
Local memory 핵심 파라미터 확인 3-3. 공유 메모리 실제 사용량 확인
-- shared_buffers 사용 현황 (pg_buffercache 확장 설치 필요) CREATE EXTENSION IF NOT EXISTS pg_buffercache; SELECT c.relname, COUNT(*) AS buffers, ROUND(COUNT(*) * 8 / 1024.0, 2) AS size_mb FROM pg_buffercache b JOIN pg_class c ON c.relfilenode = b.relfilenode GROUP BY c.relname ORDER BY buffers DESC LIMIT 10;
shared_buffers 사용 현황
4. WAL(Write-Ahead Log) 동작 원리
- 오라클의 Redo Log에 대응하는 개념
- 핵심 원칙: 데이터 파일보다 WAL을 먼저 기록 → 장애 시 WAL로 복구 가능
항목 오라클 Redo Log PostgreSQL WAL 저장 위치 $ORACLE_BASE/oradata/…/redo*.log $PGDATA/pg_wal/ 기록 주체 LGWR 프로세스 walwriter 프로세스 버퍼 Redo Log Buffer (SGA) wal_buffers 순환 사용 고정 크기 그룹 순환 세그먼트 파일 순환 (기본 16MB/개) 아카이브 ARCHIVELOG 모드 archive_mode = on 복제 활용 Data Guard Streaming Replication 4-1. WAL 관련 파라미터 확인
-- WAL 레벨 및 아카이브 설정 확인 SHOW wal_level; -- minimal / replica / logical SHOW archive_mode; -- on / off SHOW max_wal_size; -- 체크포인트 사이 최대 WAL 누적 크기 SHOW min_wal_size; -- 재사용할 WAL 세그먼트 최소 유지 크기 SHOW checkpoint_timeout; -- 강제 체크포인트 주기 (기본 5min) -- [결과 예시] -- wal_level = replica -- archive_mode = off -- max_wal_size = 1GB -- min_wal_size = 80MB -- checkpoint_timeout = 5min
WAL 관련 파라미터 확인 4-2. WAL 파일 직접 확인
-- pg_wal 디렉토리 확인 (OS 터미널) ls -lh /var/lib/postgresql/14/main/pg_wal/ -- WAL 세그먼트 파일 이름 구조 -- 000000010000000000000001 -- [타임라인ID 8자리][LSN High 8자리][LSN Low 8자리] -- 현재 WAL 위치(LSN) 확인 SELECT pg_current_wal_lsn(); -- 특정 LSN에 해당하는 WAL 파일명 확인 SELECT pg_walfile_name('0/1A3B2C4D');
pg_wal 디렉토리 확인 
현재 WAL 위치 확인 및 특정 LSN에 해당하는 WAL 파일명 확인 4-3. WAL 쓰기 동작 흐름
-- 트랜잭션 커밋 시 WAL이 어떻게 기록되는지 추적 -- synchronous_commit 파라미터가 핵심 SHOW synchronous_commit; -- on (기본값): COMMIT 시 WAL이 디스크에 fsync될 때까지 대기 → 데이터 안전, 지연 발생 -- off : WAL 버퍼 기록 후 바로 응답 → 빠르지만 장애 시 최근 트랜잭션 손실 가능 -- local : 로컬 디스크 기록만 보장 (복제 환경에서 replica 쪽은 비동기) -- WAL 통계 확인 SELECT stat.name, stat.setting FROM pg_settings stat WHERE name LIKE 'wal%' ORDER BY name;
synchronous_commit 파라미터 확인 후 WAL 통계 확인
5. MVCC — 오라클 Undo와의 구조적 차이
- MVCC(Multi-Version Concurrency Control): 동시성 제어를 위해 데이터의 여러 버전을 유지하는 방식
- 오라클과 PostgreSQL 모두 MVCC를 사용하지만 버전을 저장하는 위치가 근본적으로 다름
항목 오라클 PostgreSQL 구버전 저장 위치 Undo 세그먼트 (별도 공간) Heap(테이블 파일) 내 Dead Tuple 구버전 관리 방식 Undo 세그먼트 순환 재사용 VACUUM이 주기적으로 Dead Tuple 정리 읽기 일관성 Undo에서 읽기 시점 버전 재구성 트랜잭션 ID(xmin/xmax)로 가시성 판단 롤백 방식 Undo로 원상 복구 Dead Tuple이 그냥 남음 (VACUUM 정리) 공간 반환 Undo 자동 순환 VACUUM 실행 필요 5-1. MVCC 핵심 — xmin / xmax
-- PostgreSQL은 각 행(tuple)에 숨겨진 시스템 컬럼을 갖고 있음 -- xmin: 이 행을 INSERT한 트랜잭션 ID -- xmax: 이 행을 DELETE/UPDATE한 트랜잭션 ID (없으면 0) -- testuser로 testdb 접속 psql -U testuser -d testdb -h 127.0.0.1 -- 실습용 테이블 생성 CREATE TABLE mvcc_test ( id SERIAL PRIMARY KEY, name VARCHAR(50) ); INSERT INTO mvcc_test (name) VALUES ('Alice'), ('Bob'), ('Charlie'); -- xmin, xmax 직접 확인 SELECT xmin, xmax, id, name FROM mvcc_test; -- [결과 예시] -- xmin | xmax | id | name -- -------+------+----+--------- -- 766 | 0 | 1 | Alice ← xmin=766: 트랜잭션 766이 INSERT, xmax=0: 아직 삭제 안 됨 -- 766 | 0 | 2 | Bob -- 766 | 0 | 3 | Charlie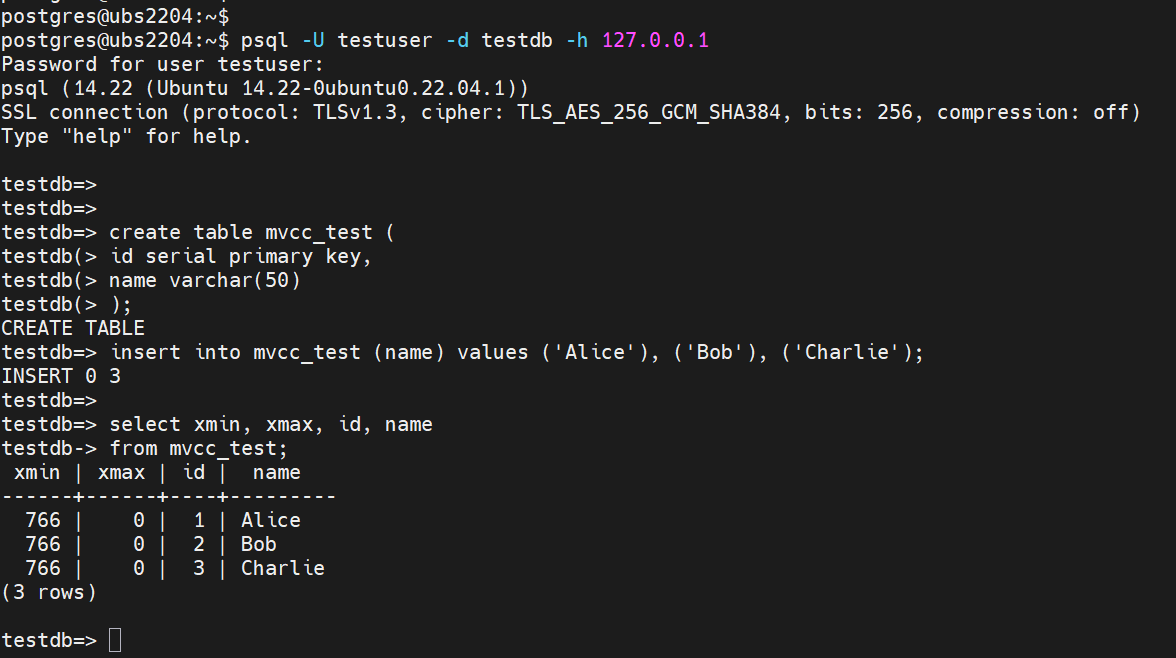
testdb에서 실습용 테이블 생성 후 insert 작업, xmin 및 xmax 확인 5-2. UPDATE 시 Dead Tuple 생성 확인
-- UPDATE 실행 UPDATE mvcc_test SET name = 'Alice_Updated' WHERE id = 1; -- xmin/xmax 다시 확인 SELECT xmin, xmax, id, name FROM mvcc_test; -- [결과 예시] -- xmin | xmax | id | name -- -------+------+----+--------------- -- 766 | 0 | 2 | Bob -- 766 | 0 | 3 | Charlie -- 767 | 0 | 1 | Alice_Updated ← 새 버전: xmin=767로 새로 INSERT된 것과 동일
5-3. Dead Tuple 누적 확인
-- testdb에서 pg_stat_user_tables로 mvcc_test DB의 Dead Tuple 수 확인 SELECT relname, n_live_tup AS live_tuples, n_dead_tup AS dead_tuples, last_vacuum, last_autovacuum FROM pg_stat_user_tables WHERE relname = 'mvcc_test';
mvcc_test의 Dead Tuple 수 확인 5-4. Dead Tuple xmin/xmax 확인
-- 슈퍼유저(postgres)로 testdb 접속 psql -d testdb -- 1. 확장 모듈 설치 CREATE EXTENSION IF NOT EXISTS pageinspect; -- 2. Dead Tuple(t_xmax가 0이 아닌 값) 및 Live Tuple xmin/xmax 확인 SELECT lp, t_xmin, t_xmax, t_ctid, FROM heap_page_items(get_raw_page('mvcc_test', 0));
슈퍼유저로 testdb 접속 후 확장 모듈 설치 
Dead Tuple과 Live Tuple xmin/xmax 확인
6. VACUUM — PostgreSQL만의 유지보수 메커니즘
- 오라클에는 없는 PostgreSQL 고유의 개념
- Dead Tuple이 테이블 안에 쌓이는 MVCC 구조 때문에 반드시 필요한 정리 작업
항목 설명 VACUUM Dead Tuple 정리 → 공간을 재사용 가능 상태로 표시 (OS 반환 아님) VACUUM FULL Dead Tuple 정리 + 테이블 파일 크기 실제 축소 (테이블 잠금 발생) ANALYZE 테이블 통계 갱신 → 플래너가 올바른 실행계획 수립에 사용 VACUUM ANALYZE 위 두 작업 동시 수행 autovacuum 백그라운드에서 자동으로 VACUUM/ANALYZE 수행 6-1. 수동 VACUUM 실습
-- Dead Tuple 대량 생성 UPDATE mvcc_test SET name = name || '_v2'; UPDATE mvcc_test SET name = name || '_v3'; -- Dead Tuple 누적 확인 SELECT relname, n_live_tup, n_dead_tup FROM pg_stat_user_tables WHERE relname = 'mvcc_test';
Dead Tuple 6개 생성 후 누적 확인 -- VACUUM 실행 (VERBOSE로 상세 출력) VACUUM VERBOSE mvcc_test; -- [출력 예시] INFO: vacuuming "public.mvcc_test" INFO: table "mvcc_test": found 7 removable, 3 nonremovable row versions in 1 out of 1 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 776 Skipped 0 pages due to buffer pins, 0 frozen pages. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. VACUUM -- VACUUM 후 Dead Tuple 감소 확인 SELECT relname, n_live_tup, n_dead_tup FROM pg_stat_user_tables WHERE relname = 'mvcc_test';
VACUUM 실행 후 Dead Tuple 감소 확인 6-2. autovacuum 설정 확인
-- autovacuum 관련 파라미터 확인 SELECT name, setting, unit, short_desc FROM pg_settings WHERE name LIKE 'autovacuum%' ORDER BY name; -- 핵심 파라미터 설명 -- autovacuum : on/off (기본 on — 끄면 안 됨) -- autovacuum_vacuum_threshold : Dead Tuple이 이 수 이상이면 VACUUM 트리거 (기본 50) -- autovacuum_vacuum_scale_factor: Dead Tuple 비율 기준 (기본 0.2 = 전체 행의 20%) -- autovacuum_analyze_threshold : ANALYZE 트리거 기준 (기본 50) -- autovacuum_vacuum_cost_delay : autovacuum I/O 조절 (기본 2ms) -- VACUUM 트리거 조건: -- n_dead_tup > autovacuum_vacuum_threshold + (autovacuum_vacuum_scale_factor × n_live_tup) -- 예시: live tuple 100개인 경우 -- 조건: n_dead_tup > 50 + (0.2 × 100) > 50 + 20 > 70 -- → Dead Tuple이 71개 이상이면 VACUUM 실행
autovacuum 관련 파라미터 조회 결과 6-3. Transaction ID Wraparound — 운영에서 반드시 알아야 할 개념
-- PostgreSQL의 트랜잭션 ID(XID)는 32비트 정수 → 약 21억 개 사용 후 순환 -- [번호표 비유] -- 트랜잭션이 실행될 때마다 번호표를 하나씩 뽑음 (1번, 2번, 3번 ...) -- 21억 번을 다 쓰면 다시 1번부터 시작(순환) -- [문제] -- 순환 전: 500번 트랜잭션이 쓴 데이터 = '과거 데이터' → 정상 -- 순환 후: 500번 트랜잭션이 쓴 데이터를 -- '아직 오지 않은 미래 트랜잭션의 데이터'로 오인 -- → 데이터가 안 보이거나 손실되는 심각한 장애 발생 -- [VACUUM의 역할 — Freeze] -- VACUUM은 Dead Tuple 청소 외에 Freeze 작업도 수행 -- Freeze = 오래된 데이터에 "번호표 순환에 영향받지 않는 영구 데이터" 도장 찍기 -- 도장이 찍힌 행은 번호표가 몇 번을 순환해도 항상 "과거 데이터"로 올바르게 인식됨 -- [실무에서 확인할 것] -- xid_age가 20억에 가까워지면 autovacuum이 제대로 안 돌고 있다는 신호 -- 위험 수준 도달 시 PostgreSQL이 새 트랜잭션을 거부하고 강제 VACUUM 요구 -- → autovacuum을 절대 꺼서는 안 되는 핵심 이유-- 현재 트랜잭션 ID 및 Wraparound까지 남은 여유 확인 SELECT datname, age(datfrozenxid) AS xid_age, 2147483647 - age(datfrozenxid) AS xid_remaining FROM pg_database ORDER BY xid_age DESC; -- xid_age가 20억에 가까워지면 경고 신호 -- autovacuum이 정상 동작하면 일반적으로 수백만 수준에서 관리됨
현재 트랜젝션 ID 및 wraparound까지 남은 여유
실습 핵심 요약
주제 핵심 포인트 프로세스 구조 멀티 프로세스 — 접속마다 백엔드 프로세스 fork postmaster 모든 PostgreSQL 프로세스의 부모 — 클라이언트 접속 수락 및 Background Process 관리 checkpointer dirty page → 디스크 flush (오라클 DBWn + CKPT 역할) walwriter WAL 버퍼 → pg_wal 기록 (오라클 LGWR 역할) autovacuum launcher Dead Tuple 감지 후 worker 실행 (오라클 SMON 일부 역할) shared_buffers 공유 버퍼 캐시 — 실무 권장값: 전체 RAM의 25% work_mem 백엔드 프로세스별 정렬/해시 메모리 — max_connections와 함께 설계 필요 WAL 쓰기 전 로그 — 장애 복구·복제의 기반 (오라클 Redo Log 대응) MVCC 방식 Dead Tuple을 테이블 파일 내부에 보관 (오라클은 Undo 세그먼트) xmin / xmax 행 가시성 판단 기준 — 트랜잭션 ID로 버전 관리 VACUUM Dead Tuple 정리 — PostgreSQL 고유 유지보수 메커니즘 autovacuum 기본 on — 운영 환경에서 절대 끄면 안 됨 XID Wraparound 21억 트랜잭션 순환 문제 — VACUUM Freeze로 방지 'DB 스터디 > PostgreSQL' 카테고리의 다른 글
PostgreSQL 02: 스키마 & DML 실습 (오라클 비교) (0) 2026.03.10 PostgreSQL 01: PostgreSQL 14 설치 및 기본 환경 확인 (0) 2026.03.10